基於預訓練的低光圖像增強Transformer
基於預訓練的低光圖像增強Transformer

圖形摘要
摘要
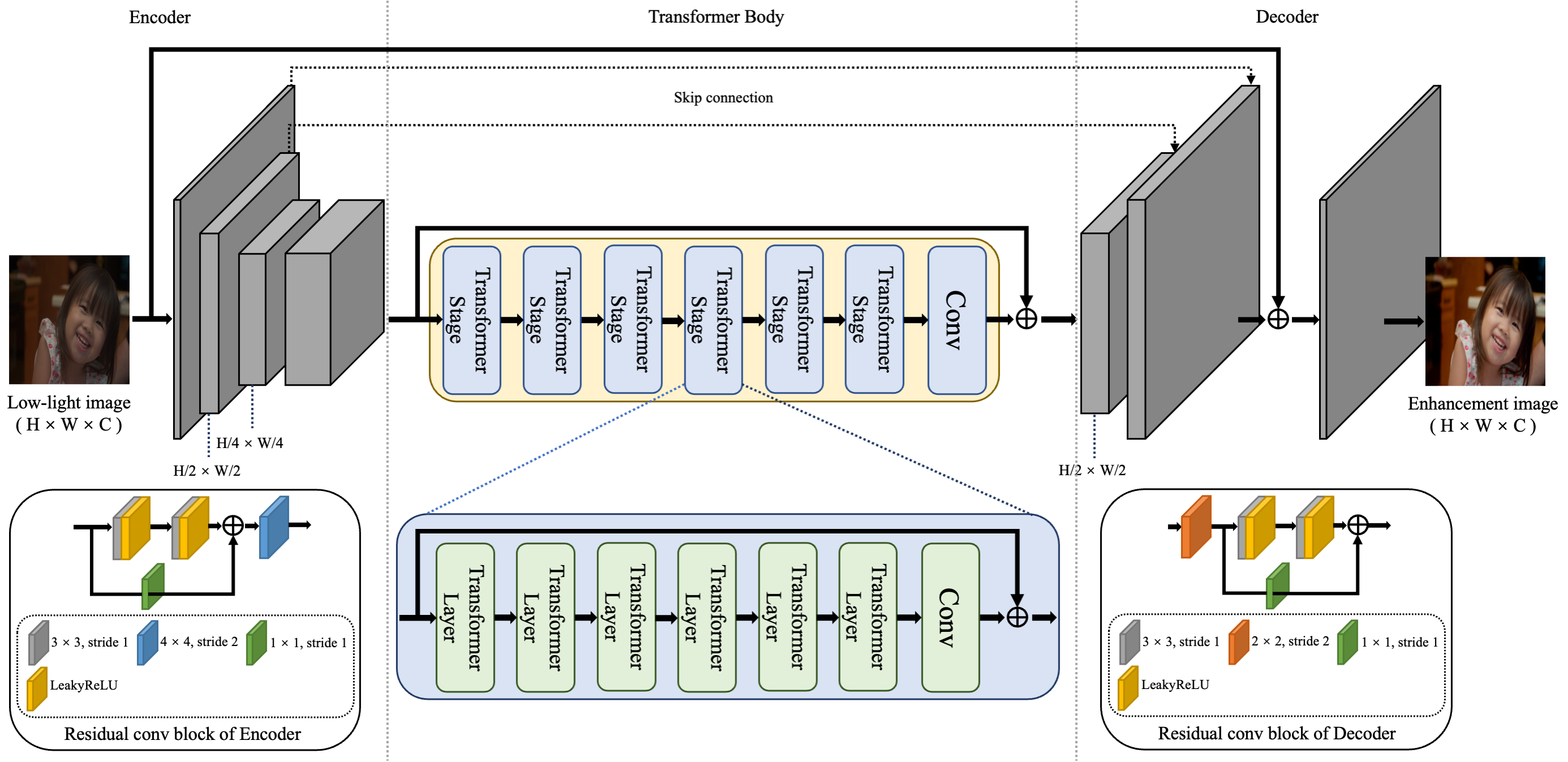
低光圖像增強是一個長期的低階視覺問題,因為低光圖像通常存在嚴重的美學品質缺陷。當前基於深度神經網路的低光圖像增強方法在這項任務上已取得顯著進展。不同於主流的基於CNN方法,我們提出了一個有效的低光增強解決方案,靈感來自在各種任務中展現卓越性能的Transformer,旨在解決此類問題。此解決方案的關鍵包括一個圖像合成流水線和一個強大的基於Transformer的預訓練模型,命名為LIET。具體而言,圖像合成流水線由光照模擬和真實噪聲模擬組成,能夠生成更真實的低光圖像,以緩解資料稀缺的瓶頸。LIET包含一對簡化的基於CNN的編碼器/解碼器和一個Transformer主體,能以相對較低的計算成本有效進行全局/局部上下文特徵提取。我們通過廣泛的實驗全面評估了所提出的方法,結果顯示我們的解決方案與最先進的方法具有高度競爭力。所有程式碼將很快發布。
。")


最後更新於