NVIDIA DALI踩坑教程

初見
事情的起因還要追溯到很久之前看了一篇論文,論文的核心就是討論預訓練策略在低層視覺任務中的作用。既然是預訓練策略,那就不可避免的要用規模大一點的資料集,之所以預訓練這些年在低層視覺任務中鮮被應用的,其主要的原因就是缺乏大規模資料集。這篇論文主要針對低層視覺任務中的SR(超解析度)、DeRain(去雨)和DeNoise(去噪)三個任務,作者利用ImageNet中的影象作為基準影象,並在此基礎上利用雙三次插值得到低解析度影象用於SR任務,將雨紋和高斯噪聲直接加入到乾淨的基準影象中用於DeRain和DeNoise任務。
但是論文中卻忽略了低層視覺中一個非常重要的問題,即低光增強任務(Low-light Image Enhancement)。我覺得主要問題就是低光增強任務中所用到的配對影象資料集是很難獲得的,特別是用ImageNet來生成,更是難上加難。其一,低光環境是個很複雜的環境,不是簡單調低影象的亮度就能實現的,在低光環境下拍攝的影象往往是有的地方暗有的地方亮;其二,低光環境下攝得的影象往往伴隨著各種複雜的噪聲,簡單的往影象上疊加噪聲可能並不真實。前不久我克服了這兩個問題,成功從ImageNet/VOC/COCO/IAPR/StreetScenes這五個資料集中挑選一些合適的影象構造了一個大規模配對的暗光影象資料集,其中共包含了153,856對暗光/正常光影象(具體資料集是如何構造的今天就不贅述了,等論文發表後我會詳細跟大家解釋)。我們知道,PyTorch中提供了torch.utils.data.Dataset(*args, **kwds)和torch.utils.data.DataLoader(dataset, ...)這兩個類來實現資料集的構建和資料的載入,但是這兩個類都是作用在CPU上的。然而我們的預訓練資料集的規模達到了153,856*2張,用CPU來載入速度實在太慢了,在後續訓練的過程中可能會導致模型等待資料傳入的情況,即模型已經訓練完一個batch的資料了,但是下一個batch的資料還在載入,沒能及時傳到模型中,這樣會導致GPU的利用率顯著下降。也就是說不僅會降低模型訓練的速度,同時也沒能完全壓榨出顯示卡等硬體的效能,是一件價效比極低的事情。下面舉個🌰(例子):
import os
import torch
import torch.nn as nn
from PIL import Image
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader, random_split
torch.__version__
DATA_DIR = "/home/jensen/workspace/DATASETS/SYNTHETIC_DATA"
BATCH_SIZE = 128
IMAGE_SIZE = 192
syn_trans = transforms.Compose([
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.ToTensor(),
])
class Syn_Dataset(nn.Module):
def __init__(self, low_path, high_path, transforms=None):
self.low_path = low_path
self.high_path = high_path
self.transforms = transforms
def __getitem__(self, idx):
low_files = os.listdir(self.low_path)
high_files = os.listdir(self.high_path)
low_image = Image.open(os.path.join(self.low_path, low_files[idx]))
high_image = Image.open(os.path.join(self.low_path, high_files[idx]))
if self.transforms:
low_image = self.transforms(low_image)
high_image = self.transforms(high_image)
return low_image, high_image
def __len__(self):
return len(os.listdir(self.low_path))
dataset = Syn_Dataset(low_path=os.path.join(DATA_DIR, "low"), high_path=os.path.join(DATA_DIR, "low"), transforms=syn_trans)
train_data, val_data = random_split(dataset, (152000, 1856))
val_loader = DataLoader(val_data, batch_size=BATCH_SIZE, shuffle=True, num_workers=4)
%%time
for idx, data in enumerate(val_loader):
X, Y = data
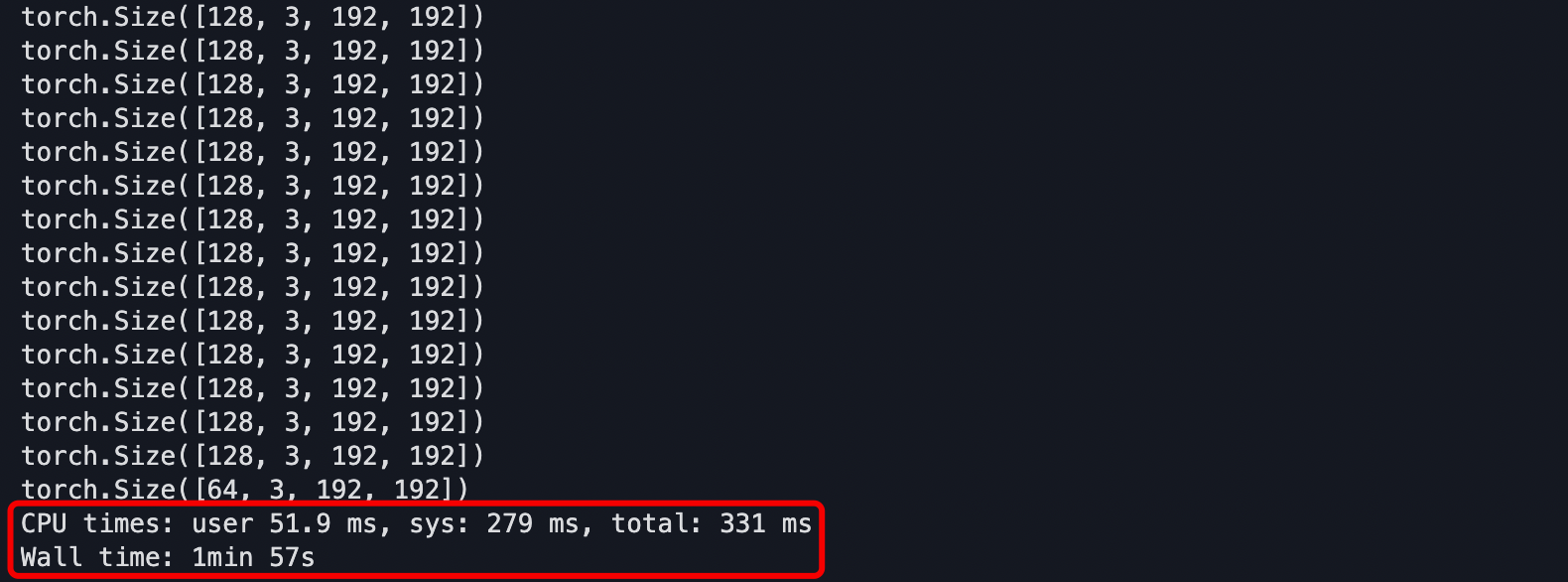
print(X.shape)上面這個例子使用PyTorch內建的DataLoader類以batch_size = 128遍歷了一遍val_dataset,並列印每個batch的尺寸。使用jupyter的%%time魔法語言來計算遍歷一遍所花費的時間,從下圖可以直觀看到,一共花費近兩分鐘完成一次遍歷。
接下來再舉個🌰:
from torchvision import models
model = models.alexnet(pretrained=False).cuda()
criterion = nn.CrossEntropyLoss()
for idx, data in enumerate(val_loader):
X, Y = data
output = model(X.cuda())
loss = criterion(out.cpu(), torch.empty(out.shape[0], dtype=torch.long).random_(1000))
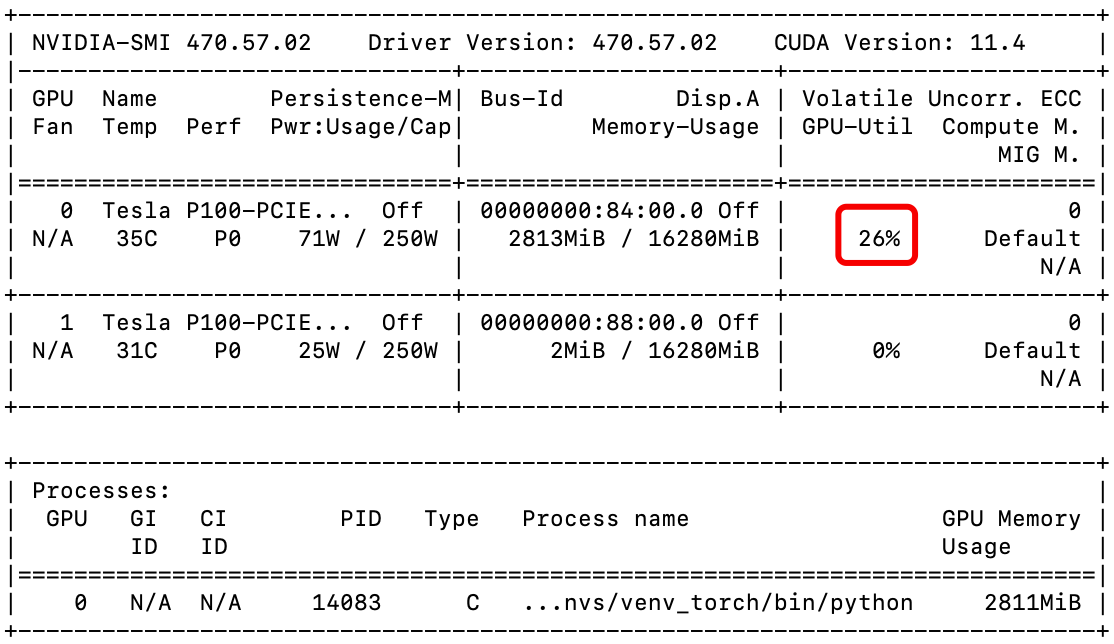
loss.backward()上面這個例子是模擬將資料輸入AlexNet中處理,從下圖中可以看到GPU的利用率很低(大多數時間都是0%)。主要原因是模型處理資料的時間比資料載入的時間更快,也就意味著模型通常要等待DataLoader將新的batch的資料傳過來,導致GPU的利用率大多數時間都處於較低的狀態甚至是空閒,嚴重拖慢模型訓練的效率。
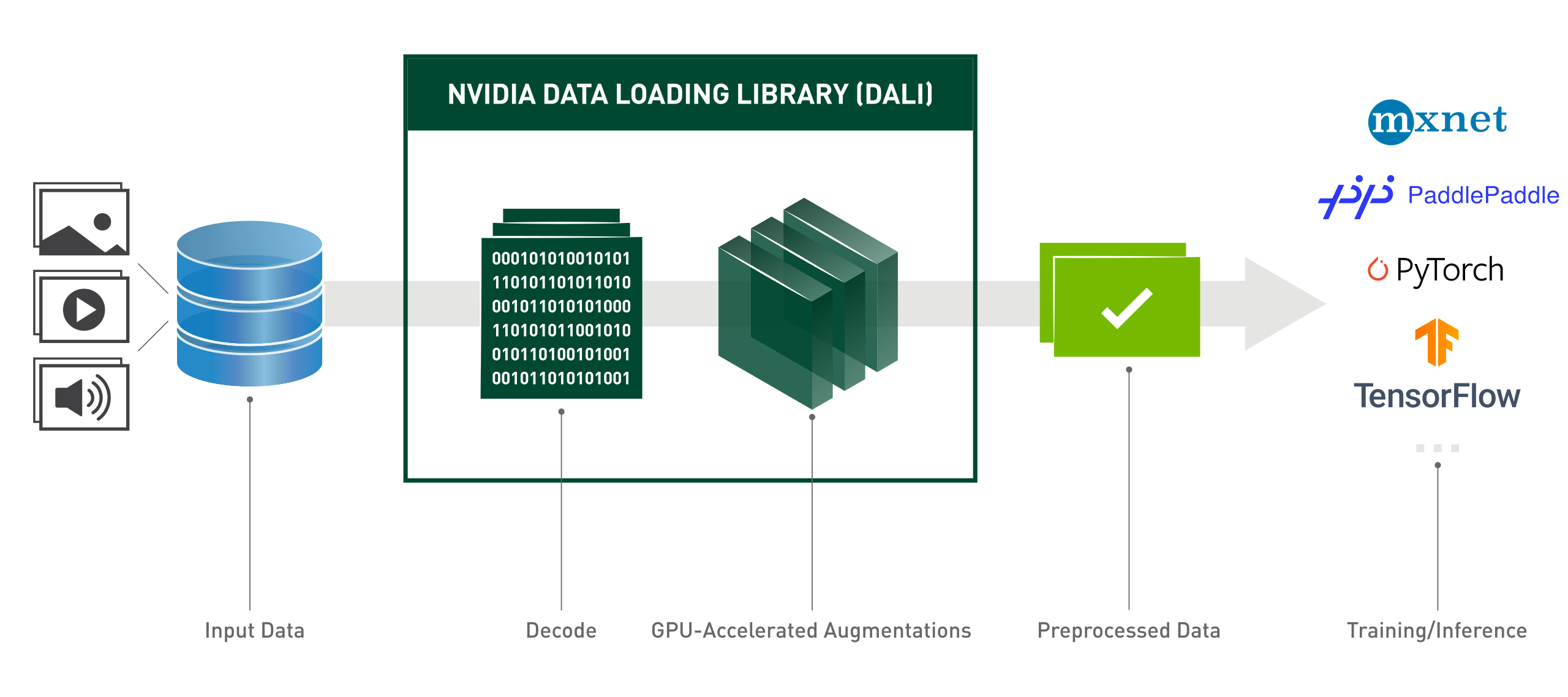
要是資料規模小的話,這點時間也不算什麼,但是我的資料規模是數十萬級別的,每一分一秒都可以說是十分珍貴的,於是我找到了一個非常nice的加速工具:NVIDIA DALI庫。
單卡環境下的NVIDIA DALI使用
(NVIDIA DALI的具體使用方式請參閱官方文件)
安裝
首先需要確定自己的cuda版本,可以在命令列中輸入nvcc -V來查詢,如下圖,cuda版本為10.2。
緊接著在命令列中輸入pip install nvidia-pyindex && pip install nvidia-dali-cuda102,請注意,這裡的cuda102正是對應了上面查詢的cuda版本10.2。
單卡環境下使用
所謂單卡環境下使用即訓練的過程中只使用一張卡,這是最簡單的形式。可以自己定義資料的迭代方式,資料的Pipeline以及載入方式。詳細細節請看程式碼:
import os
import torch
import numpy as np
from random import shuffle
import nvidia.dali.fn as fn
import nvidia.dali.types as types
from torch.utils.data import random_split
from nvidia.dali.pipeline import Pipeline
from nvidia.dali.plugin.pytorch import DALIGenericIterator, LastBatchPolicy
torch.__version__
class ExternalInputIterator(object):
def __init__(self, batch_size, files, data_dir):
self.low_dir = os.path.join(data_dir, 'low')
self.high_dir = os.path.join(data_dir, 'high')
self.batch_size = batch_size
self.files = list(files)
shuffle(self.files)
def __len__(self):
return len(self.files)
def __iter__(self):
self.i = 0
self.n = len(self.files)
return self
def __next__(self):
if self.i >= self.n:
self.__iter__()
raise StopIteration
low = []
high = []
leave_num = self.n - self.i
current_batch_size = min(self.batch_size, leave_num)
for _ in range(current_batch_size):
filename = self.files[self.i]
l = open(os.path.join(self.low_dir, filename), 'rb')
h = open(os.path.join(self.high_dir, filename), 'rb')
low.append(np.frombuffer(l.read(), dtype=np.uint8))
high.append(np.frombuffer(h.read(), dtype=np.uint8))
self.i += 1
return (low, high)
next = __next__
len = __len__
class ExternalSourcePipeline(Pipeline):
def __init__(self, data_iterator, batch_size, num_threads, device_id, img_size):
super(ExternalSourcePipeline, self).__init__(batch_size, num_threads, device_id, exec_async=False, exec_pipelined=False)
self.img_size = img_size
self.batch = batch_size
self.data_iterator = data_iterator
self.lows, self.highs = fn.external_source(source=self.data_iterator, num_outputs=2, dtype=types.UINT8)
def __len__(self):
length = len(self.data_iterator)
return (length // self.batch + 1) if (length % self.batch != 0) else (length // self.batch)
def define_graph(self):
low_decode = fn.decoders.image(self.lows, device="mixed")
high_decode = fn.decoders.image(self.highs, device="mixed")
low_resize = fn.resize(low_decode, device="gpu", resize_x=self.img_size, resize_y=self.img_size, interp_type=types.INTERP_TRIANGULAR)
high_resize = fn.resize(high_decode, device="gpu", resize_x=self.img_size, resize_y=self.img_size, interp_type=types.INTERP_TRIANGULAR)
self.low = fn.transpose(low_resize, perm=[2, 0, 1]) / 255.0
self.high = fn.transpose(high_resize, perm=[2, 0, 1]) / 255.0
return (self.low, self.high)
def iter_setup(self):
self.set_outputs(self.low, self.high)
class CustomDALIGenericIterator(DALIGenericIterator):
def __init__(self, pipelines, **kwargs):
output_maps = ['lows', 'highs']
if not isinstance(pipelines, list):
pipelines = [pipelines]
super(CustomDALIGenericIterator, self).__init__(pipelines, output_maps, **kwargs)
self.pipelines = pipelines # devices > 1 ==> pipelines > 1
def __next__(self):
batch = super(CustomDALIGenericIterator, self).__next__()
return self.parse_batch(batch)
def __len__(self):
lengths = [len(i) for i in self.pipelines]
return sum(lengths)
def parse_batch(self, batch):
lows, highs = batch[0]['lows'], batch[0]['highs']
return lows, highs
DATA_DIR = "/home/jensen/workspace/SYNTHESIS_DATA"
BATCH_SIZE = 128
IMAGE_SIZE = 192
files = os.listdir(os.path.join(DATA_DIR, 'low'))
train_files, val_files = random_split(files, (152000, 1856))
val_iter = ExternalInputIterator(batch_size=BATCH_SIZE, files=val_files, data_dir=DATA_DIR)
val_pipe = ExternalSourcePipeline(val_iter, batch_size=BATCH_SIZE, num_threads=4, device_id=0, img_size=IMAGE_SIZE)
val_loader = CustomDALIGenericIterator(val_pipe)
%%time
for idx, data in enumerate(val_loader):
X, Y = data
print(X.shape)上面的例子使用NVIDIA DALI自定義了資料的迭代方式以及載入方式,同樣使用jupyter的%%time魔法函式來計算遍歷一遍所花費的時間,如下圖所示,整個過程僅花費了不到3秒鐘。

此外,可以模擬將資料輸入AlexNet中處理,GPU的利用率也會一直穩定在85%以上,表明GPU的效能被充分利用。
多卡環境下的NVIDIA DALI使用
本文中所指的多卡環境是單機多卡環境,即在一臺機器的多個GPU上進行分散式訓練,然而多機多卡的情況並不在本文的討論範疇之內,我也確實沒有用過這種訓練方式。有關多卡環境下的使用方式也可以參考官方文件。下面直接放出我的例子吧:
import os
import nvidia.dali.fn as fn
import nvidia.dali.types as types
from torch.utils.data import random_split
from nvidia.dali.pipeline import Pipeline
from nvidia.dali.plugin.pytorch import DALIGenericIterator, LastBatchPolicy
class SyntheicDataPipeline(Pipeline):
"""
An extended Pipeline class based on the Nvidia DALI library for low-light image enhancement.
The effect of the Pipeline class is somewhat similar to the Dataset class in Pytorch and
the transforms function in torchvision. Mainly is to carry on some simple preprocessing to the input data.
Args:
batch_size (int): batch_size.
data_dir (str): the folder path of the paired image. (excluding the 'low' and' high' folders)
files (list): A list of paired image filenames.
image_size (int | tuple): image size after resize operation. Default: 192
num_threads (int): number of CPU threads used by the pipeline. Default: 2
device_id (int): id of GPU used by the pipeline. Default: 0
seed (int): seed used for random number generation. Default: -1
shard_id (int): index of the shard to read. Default: 0
num_shards (int): partitions the data into the specified number of parts (shards). Default: 1
random_shuffle (bool): determines whether to randomly shuffle data. Default: True
Examples:
When you have a GPU, device_id and shard_id should be set to 0 and num_shards should be set to 1.
When you have four GPU, the value range for device_id and shard_id is [0-3] (device_id and shard_id
values are usually the same), and num_shards should be set to 4.
For details, please refer to the official DALI documentation: https://docs.nvidia.com/deeplearning/dali/user-guide/docs/
or my blog (which will be updated in the near future): https://jensen.dlab.ac.cn/ .
"""
def __init__(self, batch_size, data_dir, files,
image_size=192, num_threads=-1, device_id=0, seed=-1,
shard_id=0, num_shards=1, random_shuffle=True, **kwargs):
super(SyntheicDataPipeline, self).__init__(batch_size=batch_size, num_threads=num_threads,
device_id=device_id, seed=seed, **kwargs)
self.types = ['low', 'high']
self.data_dir = [os.path.join(data_dir, name) for name in self.types]
self.files = list(files)
self.image_size = image_size
self.shard_id = shard_id
self.num_shards = num_shards
self.random_shuffle = random_shuffle
def define_graph(self):
low_inputs, _ = fn.readers.file(file_root=self.data_dir[0], files=self.files, seed=1234,
shard_id=self.shard_id, num_shards=self.num_shards,
random_shuffle=self.random_shuffle, pad_last_batch=True,
name="main_reader")
high_inputs, _ = fn.readers.file(file_root=self.data_dir[1], files=self.files, seed=1234,
shard_id=self.shard_id, num_shards=self.num_shards,
random_shuffle=self.random_shuffle, pad_last_batch=True)
inputs = {'low': low_inputs, 'high': high_inputs}
images = {x: fn.decoders.image(inputs[x], device="mixed") for x in self.types}
resizes = {x: fn.resize(images[x], device="gpu", resize_x=self.image_size,
resize_y=self.image_size, interp_type=types.INTERP_TRIANGULAR)
for x in self.types}
self.tensors = {x: fn.transpose(resizes[x], perm=[2, 0, 1]) / 255.0 for x in self.types}
return (self.tensors['low'], self.tensors['high'])
def iter_setup(self):
self.set_outputs(self.tensors['low'], self.tensors['high'])
class SyntheicDataIterator(DALIGenericIterator):
"""
An extended Iterator class based on the Nvidia DALI library for low-light image enhancement.
The effect of the Iterator class is somewhat similar to the Dataloader class in Pytorch.
Args:
pipelines (nvidia.dali.Pipeline): pipelines.
reader_name (str): name of the reader which will be queried to the shard size,
number of shards and all other properties necessary to count
properly the number of relevant and padded samples that iterator
needs to deal with.
last_batch_policy (int): strategy for processing the last batch data. (especially if the
size of the last batch data is smaller than batch_size)
output_map (list): list of strings which maps consecutive outputs of DALI pipelines to user specified name.
Example:
loader = SyntheicDataIterator(...)
for idx, data in enumerate(loader):
low, high = data
...
For details, please refer to the official DALI documentation: https://docs.nvidia.com/deeplearning/dali/user-guide/docs/
or my blog (which will be updated in the near future): https://jensen.dlab.ac.cn/ .
"""
def __init__(self, pipelines, reader_name, last_batch_policy,
output_map=['low', 'high'], **kwargs):
super(SyntheicDataIterator, self).__init__(pipelines=pipelines, output_map=output_map,
reader_name=reader_name, last_batch_policy=last_batch_policy,
**kwargs)
def _parse_data(self, data):
low_data, high_data = data[0]['low'], data[0]['high']
return low_data, high_data
def __next__(self):
data = super(SyntheicDataIterator, self).__next__()
return self._parse_data(data)
def __len__(self):
return super(SyntheicDataIterator, self).__len__()
DATA_DIR = "/home/jensen/workspace/SYNTHESIS_DATA"
BATCH_SIZE = 128
IMAGE_SIZE = 192
files = os.listdir(os.path.join(DATA_DIR, 'low'))
train_files, val_files = random_split(files, (152000, 1856))
pipe = SyntheicDataPipeline(batch_size=BATCH_SIZE, num_threads=4, device_id=0,
seed=1234, data_dir=DATA_DIR, files=val_files,
image_size=IMAGE_SIZE, shard_id=0, num_shards=1)
val_loader = SyntheicDataIterator(pipe, reader_name="main_reader", auto_reset=True,
last_batch_policy=LastBatchPolicy.PARTIAL)
for idx, data in enumerate(val_loader):
X, Y = data
print(X.shape)上面的例子其實還是單機單卡的環境,但是隻要稍微修改一下就可以實現單機多卡。即將SyntheicDataPipeline類中的device_id和shard_id以及num_shards這三個引數稍作修改。device_id很好理解了,例如一臺機器有四張GPU,則device_id分別為0、1、2、3。假如在第二張GPU上進行運算,則device_id就是2,此外shard_id一般與device_id保持一致,它是指第幾個分片(分散式訓練的實質就是將一個大batch的資料均分到每個GPU上來並行運算,因此第一張GPU上輸入的資料應當就是均分資料得到的第一個分片)。num_shards這個引數也很好理解,它的意思即一共有多少張GPU。雖然看起來很簡單,但是還是有三個引數需要修改,似乎還是有點麻煩,但是不用擔心,實際上這些引數都是不需要人為去設定。因為通常分散式訓練都需要從命令列傳入一個引數--nproc_per_node,透過這一個引數都能自適應的完成上述引數的修改,在實際訓練的時候,只需做如下修改即可:device_id=args.local_rank、shard_id=args.local_rank、num_shards=args.world_size。
好了,本篇部落格到這裡就應該要結束了,本文中提到的方法通常都能適用於各種深度學習任務,只是不同的任務在資料讀取上可能會有一些異同,但我相信這些問題都可以透過參閱官方文件中的nvidia.dali.fn使用說明來解決。接下來如果有時間的話我會再介紹一下如何使用NVIDIA APEX庫來實現分散式訓練以及如何將NVIDIA DALI和APEX庫結合起來使用。