Cython基礎

入門教程
Cython概念
Cython本質上就是具有C資料型別的Python。
除了極少數例外,幾乎所有的Python程式碼都是有效的Cython程式碼。Cython的編譯器會把程式碼轉換成等效於呼叫Python/C API的C程式碼。
由於Cython的引數和變數可以背宣告為具有C資料型別,因此可以自由地混用操作Python值和C值的程式碼,而Cython會自動轉換需要轉換的地方。此外,Python中的引用計數儲存和錯誤檢查也是自動的,而且Python的異常處理機制,包括try-except和try-finally同樣可行,即使是在操作C資料時。
Cython的第一個程式
Cython可以接受幾乎所有有效的Python原始檔,因此在Cython的啟程之路上最大的攔路虎之一就是如何去編譯拓展檔案。
首先從標準的Python Hello, World開始:
print("Hello, World")將這段程式碼儲存為helloworld.pyx。現在需要建立一個setup.py,這就像是一個Python的Makefile,因此setup.py應該像這樣:
from distutils.core import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("helloworld.pyx")
)接著使用下面的命令列來建立Cython檔案:
python setup.py build_ext --inplace在類Unix系統中,這行命令會在你的本地資料夾中建立一個叫做helloworld*.so的檔案。在Windows系統中,它叫helloworld*.pyd。現在執行Python直譯器,然後把這個檔案當成一個普通的Python模組簡單的import它就可以使用了:
import helloworldHello, World恭喜!此時你已經知道如何去建立一個Cython拓展了,但是這個例子會給人一種不知道Cython有何優勢的感覺,所以接下來介紹更有現實意義的例子。
Pyximport模組
如果Cython模組不需要任何外部的C庫或者特殊的安裝方式,那便可以直接使用pyximport模組。該模組由Paul Prescod開發,用來直接使用import來載入*.pyx檔案,而不需要在每次更改程式碼的時候都重新執行一遍setup.py檔案。pyximport模組的使用方式如下:
import pyximport; pyximport.install()
import helloworldHello, Worldpyximport模組也支援對普通Python模組的實驗性編譯,這可以使得在Python匯入每個*.pyx和*.py模組上自動執行Cython,包括標準庫和被安裝的包。Cython在編譯大量Python模組的時候也會經常失敗,此時import機制將會回溯,轉而去載入Python源模組:
import pyximport; pyximport.install(pyimport=True)(注意,這種方式現已不推薦!)
例子:字串轉整數
在之前Python基礎中有一個簡單的字串轉整數的例子:
from functools import reduce
DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
def str2int(s):
def fn(x, y):
return x * 10 + y
def char2num(s):
return DIGITS[s]
return reduce(fn, map(char2num, s))現在可以跟著上面Hello, World的例子照葫蘆畫瓢。首先將檔案拓展名更改為str2int.pyx,接下來建立setup.py檔案:
from distutils.core import setup
from Cython.Build import cythonize
setup(
ext_modules=cythonize("str2int.pyx"),
)建立拓展的命令與helloworld.pyx的例子相同:
python setup.py build_ext --inplace使用拓展的方式也很簡單:
import str2int
str2int.str2int('2021111052')2021111052也可以使用pyximport模組來匯入拓展:
import pyximport; pyximport.install()
import str2int
str2int.str2int('2021111052')2021111052Cython特性
下面透過一個小例子來介紹Cython的特性。
# 載入Cython擴充套件
%load_ext Cython
%%cython
def primes(int nb_primes):
cdef int n, i, len_p
cdef int p[1000]
if nb_primes > 1000:
nb_primes = 1000
len_p = 0 # p中當前元素的數量
n = 2
while len_p < nb_primes:
# 是否是質數?
for i in p[:len_p]:
if n % i == 0: # 存在一個因數則跳過,不是質數
break
else: # 一個因數都沒有,是質數
p[len_p] = n
len_p += 1
n += 1
result_as_list = [prime for prime in p[:len_p]]
return result_as_list
primes(10)[2, 3, 5, 7, 11, 13, 17, 19, 23, 29]可以發現,函式的開始部分就像普通的Python函式定義,除了引數nb_primes被宣告為int型別,這意味著這個引數被傳入時會被轉換為C的整數型別(如果轉換失敗則是TypeError)。
在函式體中,使用了cdef語句來定義一些區域性的C變數:
...
cdef int n, i, len_p # 定義一些區域性的C變數
cdef int p[1000]
...在處理過程中,結果被儲存在一個C陣列p中,並且最後被複制到一個Python列表中:
...
p[len_p] = n # 結果被儲存在C陣列中
...
result_as_list = [prime for prime in p[:len_p]] # 複製到Python列表中
...- 注意,在上述例子中,不能建立太大的陣列,因為陣列是被分配在C函式呼叫的棧上的,而這些棧資源是有限的。如果需要更大的陣列或者這些陣列的長度只有在程式執行時才能被確定,可以使用Cython對C記憶體進行分配或者使用Numpy陣列等等進行提高效率。
在C中宣告一個靜態陣列需要在編譯時確定陣列的大小,所以程式中需要確保傳入的引數不得大於陣列的大小,否則會丟擲類似C中的段錯誤:
...
if nb_primes > 1000:
nb_primes = 1000 # 防止傳入的引數超過陣列大小
...值得注意的是下面這段程式碼:
...
for i in p[:len_p]:
if n % i == 0:
break
...這段程式碼使用候選數字依次除以已經找到的每一個質數來判斷候選數字數不是質數。因為這裡面沒有Python物件被引用,迴圈被整體翻譯成了C程式碼,所以執行速度大幅提高。請注意迭代C陣列p的方式:
...
for i in p[:len_p]: # 雖然迴圈被翻譯成C程式碼,但依然可以像操作Python列表一樣使用切片,提高執行效率
...在返回結果之前,需要先將C陣列複製到一個Python列表裡,因為Python不能讀取C陣列。Cython可以自動將很多C型別轉換為Python型別:
...
result_as_list = [prime for prime in p[:len_p]] # 複製到Python列表中
...請注意,正如Python宣告一個Python列表的形式,result_as_list沒有被顯式宣告,因此它會被視為一個Python物件。
至此,Cython的基本用法已經明瞭,但Cython究竟幫我們節省了多少工作量還是值得探究的。可以在cythonize()中傳入引數annotate=True生成一個HTML檔案:
from distutils.core import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("primes.pyx", annotate=True)
)在HTML檔案中可以發現,黃色行代表改行與Python進行互動,互動的越多顏色就越深。白色行則表示沒有與Python進行互動,該部分程式碼被完全翻譯成C程式碼。
這些黃色行會操作Python物件、生成異常或是做一些其他更高階的操作,因此都不能被翻譯成簡單快速的C程式碼,函式宣告和返回使用了Python的直譯器所以這些行也是黃色的。
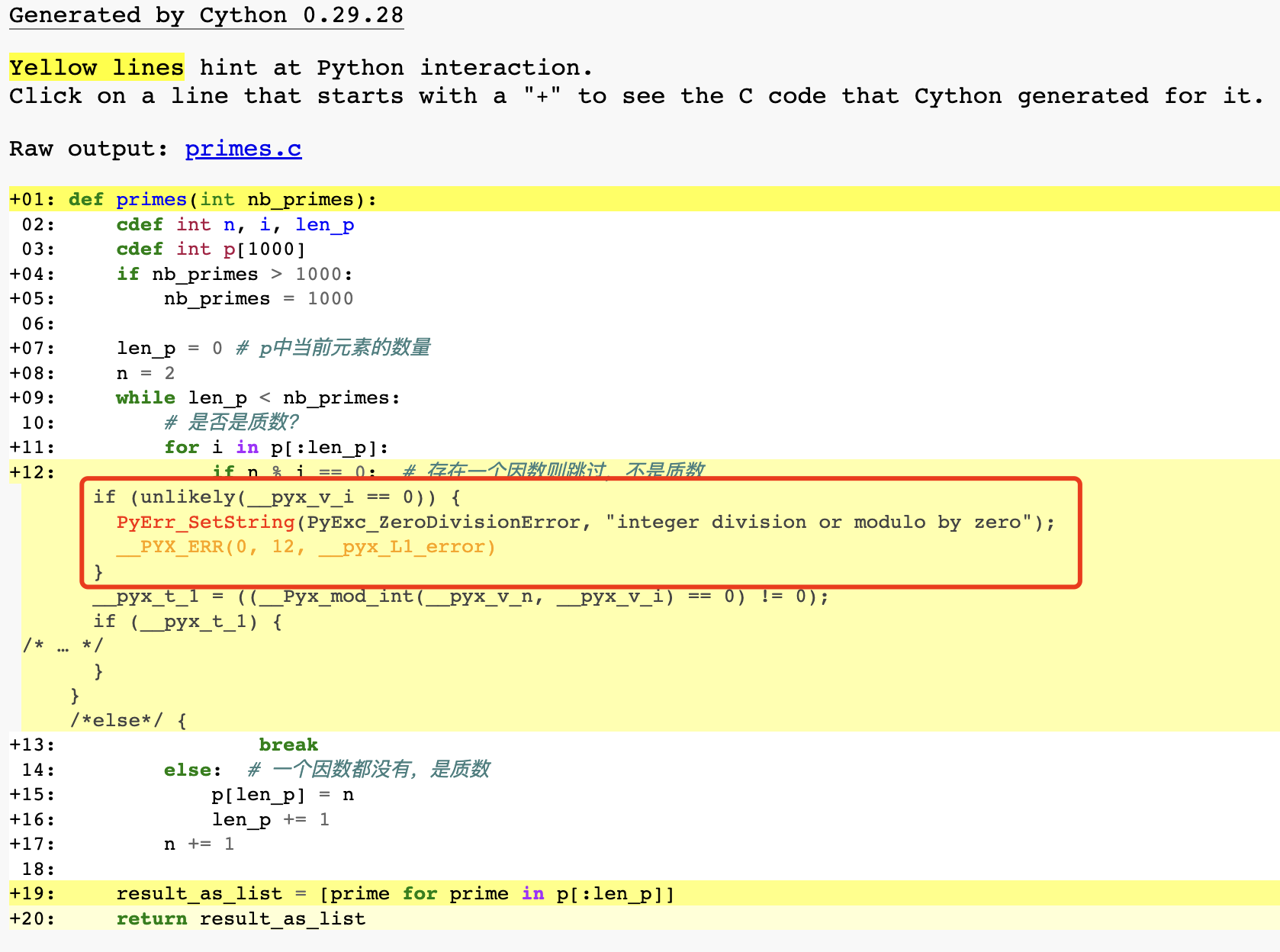
此外,按照邏輯if n % i == 0:這行語句可以直接透過C程式碼實現,為什麼會標黃呢?可以發現Cython在這裡預設使用Python在執行時的除法檢查。可以使用編譯器指令cdivision=True禁止這種檢查。
效能對比
針對上述primes的例子,下面是一個Python版的相同程式:
def primes_python(nb_primes):
p = []
n = 2
while len(p) < nb_primes:
# 是否是質數?
for i in p:
if n % i == 0:
break
# 如果迴圈中未發生break
else:
p.append(n)
n += 1
return p%%time
cython = primes(1000)CPU times: user 1.62 ms, sys: 0 ns, total: 1.62 ms
Wall time: 1.62 ms%%time
python = primes_python(1000)CPU times: user 24.6 ms, sys: 0 ns, total: 24.6 ms
Wall time: 23.7 mscython == pythonTrue從上述對比中可以發現,Cython的速度幾乎數十倍優於Python。很明顯C比Python對於CPU的快取的支援性更好,Python中一切皆物件,均以字典的形式存在,對於CPU快取是不友好的。一般來說Cython的速度會是Python的2倍到1000倍之間,具體取決於呼叫Python直譯器的次數。
C++版本的Primes
上面的Cython呼叫的都是C API,當然Cython也可以呼叫C++(部分C++的標準庫可以在Cython程式碼中被直接匯入)。下面是使用C++標準庫中vector後的primes函式:
# distutils: language=c++
from libcpp.vector cimport vector
def primes(unsigned int nb_primes):
cdef int n, i
cdef vector[int] p
p.reserve(nb_primes) # allocate memory for 'nb_primes' elements.
n = 2
while p.size() < nb_primes: # vector的size()和len()類似
for i in p:
if n % i == 0:
break
else:
p.push_back(n) # push_back is similar to append()
n += 1
return p # 在轉換到Python物件時,vector可以被自動轉換為Python列表 第一行# distutils: language=c++是編譯器指令,告訴Cython把程式碼編譯成C++,這樣就可以使用C++的特性和C++標準庫(注意,pyximport無法把Cython程式碼編譯成C++,需要使用setup.py)。
可以看到,C++的vector API和Python的列表API非常相似,在Cython中經常可以做替換。
更多在Cython中使用C++的細節請參閱在Cython中使用C++。
更多Cython語言基礎請參閱語言基礎。
中文Cython文件請參閱Cython中文文件。