Swift Learning (5) - Strings and Characters (Improved Code Version)


A string is a collection of characters, such as “Hello, world” or “albatross”. In Swift, strings are represented by the String type. There are multiple ways to access the contents of a String, such as as a collection of Character values.
The String and Character types in Swift provide a fast and Unicode-compliant way to handle text in your code. The syntax for creating and manipulating strings is similar to string operations in C, being lightweight and readable. Concatenating two strings is as simple as using the + operator. As with other values in Swift, whether a string can be modified depends on whether it is defined as a constant or a variable.
Developers can insert constants, variables, literals, and expressions into existing strings to form longer strings, a process known as string interpolation. String interpolation is especially useful when creating custom string values for display, storage, or printing.
Despite its simple syntax, the implementation of the String type in Swift is fast and modern. Every string consists of encoding-independent Unicode characters and supports accessing characters in various Unicode representations.
Note
Swift’s
Stringtype is seamlessly bridged with Foundation’sNSStringclass. Foundation also extendsStringto provide access to methods defined inNSString. This means you can call thoseNSStringmethods without any type conversion.
String Literals
You can use a predefined string value in your code as a string literal. A string literal is a fixed sequence of characters enclosed in a pair of double quotes.
String literals can be used to provide initial values for constants and variables.
let someString = "Some string literal value" // Initialize a String constant with a string literalNote that Swift infers the type of the constant someString as String because it is initialized with a string literal.
Multiline String Literals
If you need a string that spans multiple lines, use a multiline string literal: a fixed sequence of text characters enclosed in a pair of triple double quotes.
let quotation = """
The White Rabbit put on his spectacles. "Where shall I begin, please your Majesty?" he asked.
"Begin at the beginning" the King said gravely, "and go on til you come to the end; then stop."
"""
print(quotation)
---
output: The White Rabbit put on his spectacles. "Where shall I begin, please your Majesty?" he asked.
"Begin at the beginning" the King said gravely, "and go on til you come to the end; then stop."A multiline string literal includes all lines between the opening and closing triple quotes """. The string starts from the first line after the opening quotes and ends before the closing quotes. This means there are no line breaks immediately after the opening or before the closing quotes.
In the following example, the two strings are actually the same, even though the second uses the multiline string form.
let singleLineString = "These are the same."
let multiLineString = """
These are the same.
"""
print("Single-line string: \(singleLineString)")
print("Multiline string: \(multiLineString)")
---
output: Single-line string: These are the same.
Multiline string: These are the same.If your multiline string literal contains line breaks, those line breaks will also be included in the literal. If you want to break a line in your code for readability but do not want a line break in the resulting string, use a backslash \ at the end of the line as a line continuation character.
let softWrappedQuotation = """
The White Rabbit put on his spectacles. "Where shall I begin, \
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on \
till you come to the end; then stop."
"""
print("Quotation with line breaks: \(softWrappedQuotation)")
---
output: Quotation with line breaks: The White Rabbit put on his spectacles. "Where shall I begin, please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on till you come to the end; then stop."To make a multiline string literal start and end with a line break, write a line break on the first and last lines, for example:
let lineBreaks = """
This string starts with a line break.
It also ends with a line break.
"""
print(lineBreaks)
---
output:
This string starts with a line break.
It also ends with a line break.A multiline string literal can be indented to match the surrounding code. The whitespace before the closing triple quotes """ tells the Swift compiler how much whitespace to ignore on the other lines. However, if a line has more leading whitespace than the closing quotes, the extra whitespace will be included in the literal.
let linesWithIndentation = """
This line doesn't begin with whitespace.
This line begins with four spaces.
This line doesn't begin with whitespace.
""" // Four spaces before the closing quotes
print(linesWithIndentation)
---
output: This line doesn't begin with whitespace.
This line begins with four spaces.
This line doesn't begin with whitespace.In the example above, although the entire multiline string literal is indented (source code indentation), the first and last lines do not start with whitespace (actual variable value). The middle line’s indentation (source code indentation) exceeds the whitespace before the closing quotes, so the extra four spaces are included at the start of the line.
Special Characters in String Literals
String literals can contain the following special characters:
- Escape characters:
\0(null character),\\(backslash),\t(tab),\n(newline),\r(carriage return),\"(double quote),\'(single quote) Unicodescalars, written as\u{n}(lowercase u), wherenis any one to eight digit hexadecimal number and a valid Unicode code point
The following code demonstrates the use of various special characters.
let wiseWords = "\"Imagination is more important than knowledge.\" - Einstein"
let dollarSign = "\u{24}" // $, Unicode scalar U+0024
let blackHeart = "\u{2665}" // ♥, Unicode scalar U+2665
let sparklingHeart = "\u{1F496}" // 💖, Unicode scalar U+1F496
print(wiseWords)
print(dollarSign, terminator: " ")
print(blackHeart, terminator: " ")
print(sparklingHeart)
---
output: "Imagination is more important than knowledge." - Einstein
$ ♥ 💖Because multiline string literals use triple double quotes instead of a single one, you can use double quotes " directly inside a multiline string literal without needing to escape them. To use """ inside a multiline string literal, you need to use at least one escape character (in a multiline string literal, you can use \""" to escape three double quotes, or \"\"\").
let threeDoubleQuotes = """
Escaping the first quote \"""
Escaping all three quotes \"\"\"
"""
print(threeDoubleQuotes)
---
output: Escaping the first quote """
Escaping all three quotes """Extended String Delimiters
You can enclose string literals in extended delimiters so that special characters in the string are included directly rather than being interpreted as escape sequences. Place the string in quotes " and wrap it with number signs #. For example, printing the string literal #"Line 1 \n Line2"# will print the escape sequence \n rather than creating a line break.
If you want special effects for characters in the string literal, add the same number of # after the backslash \ as at the start. For example, if the string is #"Line 1 \nLine 2"# and you want a line break, use #"Line 1 \#nLine 2"# instead. Similarly, ###"Line 1 \###nLine 2"### also works.
String literals created with extended delimiters can also be multiline string literals. You can use extended delimiters to include the text """ in a multiline string, overriding the default behavior of ending the literal. For example:
let threeMoreDoubleQuotationMarks = #"""
Here are three more double quotes: """
Good! Good!
"""#
print(threeMoreDoubleQuotationMarks)
---
output: Here are three more double quotes: """
Good! Good!Initializing an Empty String
To create an empty string as an initial value, you can assign an empty string literal to a variable or initialize a new String instance.
var emptyString = "" // Empty string literal
var anotherEmptyString = String() // Initialization method
// Both strings are empty and equivalentYou can check if a string is empty by using the isEmpty property of type Bool.
if emptyString.isEmpty {
print("Nothing to see here.") // Prints "Nothing to see here."
}
---
output: Nothing to see here.String Mutability
You can modify a string by assigning it to a variable, or make it immutable by assigning it to a constant.
var variableString = "Horse"
variableString += " and carriage" // variableString is now "Horse and carriage"
print(variableString)
let constantString = "Highlander"
//constantString += " and another Highlander" // Uncommenting this line will cause a compiler error: Left side of mutating operator isn't mutable: 'constantString' is a 'let' constant
print(constantString)
---
output: Horse and carriage
HighlanderNote
In Objective-C and Cocoa, you need to choose between two different classes (
NSStringandNSMutableString) to specify whether a string can be modified.
Strings Are Value Types
In Swift, the String type is a value type. If you create a new string, assigning it to a constant or variable, or passing it into a function/method, will copy the value. In all these cases, a new copy of the string value is created, and the copy is passed or assigned, not the original string.
Swift’s default copy behavior for strings ensures that when a function/method receives a string, you own it, regardless of where it came from. You can be sure the original string will not be modified unless you do so yourself.
At compile time, the Swift compiler optimizes string usage so that actual copying only occurs when absolutely necessary. This means you get high performance while treating strings as value types.
Working with Characters
You can use a for-in loop to iterate over a string and get the value of each character in the string.
for character in "Dog!🐶" {
print(character)
}
// You can also create a standalone character constant or variable by specifying the `Character` type and assigning a character literal.
let exclamationMark: Character = "!"
// A string can be initialized by passing an array of `Character` values as an argument.
let catCharacters: [Character] = ["c", "a", "t", "!", "🐱"]
let catString = String(catCharacters)
print(catString) // Prints "cat!🐱"
---
output: D
o
g
!
🐶
cat!🐱Concatenating Strings and Characters
Strings can be concatenated (joined) together using the + operator to create a new string.
let string1 = "hello"
let string2 = " jensen"
var welcome = string1 + string2 // welcome is now "hello jensen"
print(welcome)
---
output: hello jensenYou can also use the += operator to add a string to an existing string variable.
var instruction = "look over"
instruction += string2 // instruction is now "look over jensen"
print(instruction)
---
output: look over jensenYou can use the append() method to add a character to the end of a string variable.
let questionMark: Character = "?"
welcome.append(questionMark) // welcome is now "hello jensen?"
print(welcome)
---
output: hello jensen?Note
You cannot add a string or character to an existing character variable, as a character variable can only contain a single character.
If you need to concatenate strings using multiline string literals and want each line to end with a newline character, including the last line:
let badStart = """
one
two
"""
let end = """
three
"""
print(badStart + end) // Prints two lines: one\ntwothree
let goodStart = """
one
two
"""
print(goodStart + end) // Prints three lines: one\ntwo\nthree
---
output: one
twothree
one
two
threeIn the example above, concatenating badStart and end does not produce the desired result because badStart does not end with a newline, so its last line merges with the first line of end. In contrast, goodStart ends each line with a newline, so concatenating with end results in three lines.
String Interpolation
String interpolation is a way to construct new strings by including constants, variables, literals, and expressions. Both string literals and multiline string literals can use string interpolation, where each item to be inserted is wrapped in parentheses prefixed by a backslash.
let multiplier = 3
let message = "\(multiplier) times 2.5 is \(Double(multiplier) * 2.5)" // message is "3 times 2.5 is 7.5"
print(message)
---
output: 3 times 2.5 is 7.5In the example above, multiplier is inserted into a string literal as \(multiplier). When the string is created, this placeholder is replaced with the actual value of multiplier.
The value of multiplier is also used as part of an expression later in the string. The expression Double(multiplier) * 2.5 is evaluated and the result (7.5) is inserted into the string. In this example, the expression is written as \(Double(multiplier) * 2.5) and included in the string literal.
You can use extended string delimiters to create strings that include characters you do not want to be treated as string interpolation.
print(#"Write an interpolated string in Swift using \(multiplier)."#) // Prints "Write an interpolated string in Swift using \(multiplier)."
---
output: Write an interpolated string in Swift using \(multiplier).If you want to use string interpolation inside a string with extended delimiters, add the same number of delimiters after the backslash as at the start and end.
print(#"6 times 7 is \#(6 * 7)"#) // Prints "6 times 7 is 42"
---
output: 6 times 7 is 42Note
The expression inside the parentheses in an interpolated string cannot contain an unescaped backslash
\, nor can it contain carriage returns or newlines. However, interpolated strings can contain other literals.
Unicode
Unicode is an international standard for encoding, representing, and processing text in different writing systems. It allows developers to represent almost all characters from any language in a standard format and to read and write characters in external resources such as text files or web pages. The String and Character types in Swift are fully Unicode-compliant.
Unicode Scalars
The String type in Swift is built on Unicode scalars. A Unicode scalar is a unique 21-bit number for a character or modifier, such as U+0061 for the lowercase Latin letter “a”, or U+1F425 for the baby chick emoji “🐤”. (The maximum length for UTF-32 encoding is 4 bytes, with a 21-bit number: 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX.)
Note that not all 21-bit Unicode scalar values are assigned to characters; some are reserved for future allocation or for UTF-16 encoding. Assigned scalar values usually also have a name, such as LATIN SMALL LETTER A or FRONT-FACING BABY CHICK.
Extended Grapheme Clusters
Each Character type in Swift represents an extended grapheme cluster. An extended grapheme cluster forms a single human-readable character, which consists of one or more Unicode scalars that, when combined, form a single character.
For example, the letter é can be represented by a single Unicode scalar é (LATIN SMALL LETTER E WITH ACUTE, or U+00E9). Alternatively, a standard letter e (LATIN SMALL LETTER E, or U+0065) plus a combining acute accent scalar (U+0301) together represent the same letter é. The combining accent visually transforms e into é.
In both cases, the letter é is a single Character value in Swift, representing an extended grapheme cluster. In the first case, the cluster contains a single scalar; in the second, it contains two scalars.
let eAcute: Character = "\u{E9}" // é, a single Swift Character value, an extended grapheme cluster with one scalar
let combinedEAcute = "\u{65}\u{301}" // é, an extended grapheme cluster with two scalars
print("eAcute is \(eAcute) and combinedEAcute is \(combinedEAcute)")
---
output: eAcute is é and combinedEAcute is éExtended grapheme clusters are a flexible way to represent many complex script characters as a single character value. For example, Korean syllables from the Hangul alphabet can be represented as composed or decomposed sequences. In Swift, both are represented as the same single Character value.
let precomposed: Character = "\u{D55C}" // 한
let decomposed: Character = "\u{1112}\u{1161}\u{11AB}" // ᄒ, ᅡ, ᆫ
print("precomposed value is \(precomposed), decomposed value is \(decomposed)")
---
output: precomposed value is 한, decomposed value is 한Extended grapheme clusters can include enclosing marks (such as COMBINING ENCLOSING CIRCLE, U+20DD) that surround other Unicode scalars, as a single Character value.
let enclosedEAcute: Character = "\u{E9}\u{20DD}" // enclosedEAcute is é⃝
print(enclosedEAcute)
---
output: é⃝Regional indicator symbol Unicode scalars can be combined into a single Character value, such as REGIONAL INDICATOR SYMBOL LETTER H (U+1F1ED) and REGIONAL INDICATOR SYMBOL LETTER K (U+1F1F0).
let regionalIndicatorForHK: Character = "\u{1F1ED}\u{1F1F0}" // HK
print(regionalIndicatorForHK) // regionalIndicatorForHK is 🇭🇰
---
output: 🇭🇰Counting Characters
To get the number of Character values in a string, use the count property.
let unusualMenagerie = "Koala 🐨, Snail 🐌, Penguin 🐧, Dromedary 🐫"
print("unusualMenagerie has \(unusualMenagerie.count) characters.") // Prints "unusualMenagerie has 40 characters."
---
output: unusualMenagerie has 40 characters.Note that in Swift, connecting or changing strings using extended grapheme clusters as Character values does not necessarily change the character count.
For example, if you initialize a new string with the four-character word cafe, then add a COMBINING ACUTE ACCENT (U+0301) at the end, the resulting string still has four characters, because the four characters now form café, which is still length 4.
var word = "cafe"
print("The number of characters in \(word) is \(word.count).") // Prints "The number of characters in cafe is 4."
word += "\u{301}"
print("The number of characters in \(word) is \(word.count).") // Prints "The number of characters in café is 4."
---
output: The number of characters in cafe is 4.
The number of characters in café is 4.Note
Extended grapheme clusters can consist of multiple Unicode scalars. This means different characters and different representations of the same character may require different amounts of memory to store. Therefore, characters in a Swift string do not necessarily occupy the same amount of memory. If you are working with a long string, be aware that the
countproperty must traverse all Unicode scalars to determine the character count.Also note that the character count returned by
countis not always the same as thelengthproperty of anNSStringcontaining the same characters. Thelengthproperty ofNSStringis the number of 16-bit code units in its UTF-16 representation, not the number of Unicode extended grapheme clusters.
Accessing and Modifying a String
You can access and modify a string using its properties and methods, or by using subscript syntax.
String Indices
Each String value has an associated index type, String.Index, which corresponds to the position of each Character in the string.
As mentioned earlier, different characters may occupy different amounts of memory, so to determine the position of a Character, you must traverse each Unicode scalar from the start of the string to the end. Therefore, Swift strings cannot be indexed by integers.
Use the startIndex property to get the index of the first Character in a String. Use the endIndex property to get the index after the last Character. Therefore, endIndex cannot be used as a valid subscript for a string. If the String is empty, startIndex and endIndex are equal.
You can use the index(before:) or index(after:) methods to get the index immediately before or after a given index, or use index(_:offsetBy:) to get an index at a specific offset, which avoids multiple calls to index(before:) or index(after:).
You can use subscript syntax to access the Character at a specific index in a String.
let greeting = "Jensen Jon!"
print("greeting's first character is \(greeting[greeting.startIndex]).") // J
print("The character before greeting's endIndex is \(greeting[greeting.index(before: greeting.endIndex)])") // !
print("The character after greeting's startIndex is \(greeting[greeting.index(after: greeting.startIndex)])") // e
print("The character with a offset of 7 from greeting's startIndex is \(greeting[greeting.index(greeting.startIndex, offsetBy: 7)])") // J
---
output: greeting's first character is J.
The character before greeting's endIndex is !
The character after greeting's startIndex is e
The character with a offset of 7 from greeting's startIndex is JAttempting to access a Character at an out-of-bounds index will cause a runtime error.
//greeting[greeting.endIndex] // Uncommenting will cause a runtime error: Fatal error: String index is out of bounds
//greeting.index(after: greeting.endIndex) // Uncommenting will cause a runtime error: Fatal error: String index is out of boundsThe indices property creates a range containing all the indices in the string, which can be used to access individual characters.
for index in greeting.indices {
print("\(greeting[index])", terminator: " ") // Prints "J e n s e n J o n !"
}
print("")
---
output: J e n s e n J o n ! Note
You can use the
startIndexandendIndexproperties, as well as theindex(before:),index(after:), andindex(_:offsetBy:)methods, on any type that conforms to theCollectionprotocol. In addition toString, this includesArray,Dictionary, andSet.
Inserting and Removing
Call the insert(_:at:) method to insert a character at a specific index in a string, or insert(contentsOf:at:) to insert a string at a specific index.
var friendlyGreeting = "hello"
friendlyGreeting.insert("!", at: friendlyGreeting.endIndex) // friendlyGreeting is now "hello!"
friendlyGreeting.insert(contentsOf: " there", at: friendlyGreeting.index(before: friendlyGreeting.endIndex)) // friendlyGreeting is now "hello there!"Call the remove(at:) method to remove a character at a specific index, or removeSubrange(_:) to remove a substring at a specific range.
friendlyGreeting.remove(at: friendlyGreeting.index(before: friendlyGreeting.endIndex)) // friendlyGreeting is now "hello there"
let range = friendlyGreeting.index(friendlyGreeting.endIndex, offsetBy: -6)..<friendlyGreeting.endIndex
friendlyGreeting.removeSubrange(range) // friendlyGreeting is now "hello"
print(friendlyGreeting)
---
output: helloNote
You can use the
insert(_:at:),insert(contentsOf:at:),remove(at:), andremoveSubrange(_:)methods on any type that conforms to theRangeReplaceableCollectionprotocol. In addition toString, this includesArray,Dictionary, andSet.
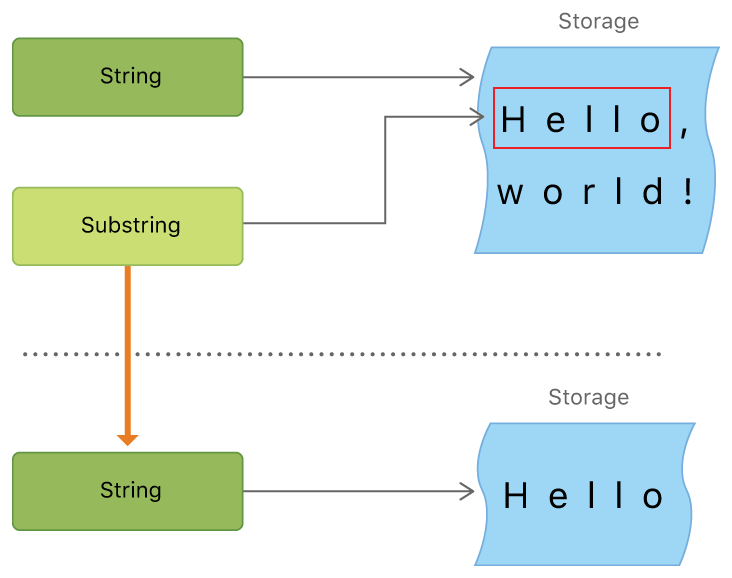
Substrings
When you get a substring from a string, for example by using subscript or methods like prefix(_:), you get an instance of Substring, not another String. Most functions on Substring are the same as on String, so you can operate on Substring and String in the same way. However, unlike String, you should only use Substring for short-term operations. If you need to store the result long-term, convert the Substring to a String instance.
let niceGreeting = "Hello, Jensen!"
let index = niceGreeting.firstIndex(of: ",") ?? niceGreeting.endIndex
let beginning = greeting[..<index] // beginning is "Hello"
// Convert the result to String for long-term storage.
let newString = String(beginning)
print("newString is \(newString).")
---
output: newString is Jense.Like String, each Substring stores its own character set in memory. The difference between String and Substring is in performance optimization: Substring can reuse the memory space of the original String or another Substring (the same optimization applies to String, but if two Strings share memory, they are equal). This optimization means you do not need to copy memory until you modify the String or Substring. As mentioned earlier, Substring is not suitable for long-term storage because it reuses the memory of the original String, which must be kept alive until the Substring is no longer used.
In the example above, niceGreeting is a String, so it has its own memory for the character set. Since beginning is a Substring of niceGreeting, it reuses the memory of niceGreeting. In contrast, newString is a String created from a Substring and has its own memory.
Note
Both
StringandSubstringconform to theStringProtocolprotocol, which means it is more convenient to use functions that operate onStringProtocol. You can pass either aStringor aSubstringto such functions.
Comparing Strings
Swift provides three ways to compare text values: string/character equality, prefix equality, and suffix equality.
String/Character Equality
Strings and characters can be compared using the equality operator == and the inequality operator !=.
let aQuotation = "We're a lot alike, you and I."
let sameQuotation = "We're a lot alike, you and I."
if aQuotation == sameQuotation {
print("These two strings are considered equal.") // Prints "These two strings are considered equal."
}
---
output: These two strings are considered equal.If two strings (or two characters) have standard-equal extended grapheme clusters, they are considered equal. As long as the extended grapheme clusters have the same linguistic meaning and appearance, they are considered standard equal, even if they are made up of different Unicode scalars.
For example, LATIN SMALL LETTER E WITH ACUTE (U+00E9) is standard equal to LATIN SMALL LETTER E (U+0065) followed by COMBINING ACUTE ACCENT (U+0301). Both represent the character é, so they are considered standard equal.
let eAcuteQuestion = "Voluez-vous un caf\u{E9}?"
let combinedEAcuteQuestion = "Voluez-vous un caf\u{65}\u{301}?"
if eAcuteQuestion == combinedEAcuteQuestion {
print("These two strings are considered equal.") // Prints "These two strings are considered equal."
}
---
output: These two strings are considered equal.In contrast, the English LATIN CAPITAL LETTER A (U+0041) is not equal to the Russian CYRILLIC CAPITAL LETTER A (U+0410). The two characters look the same but have different linguistic meanings.
let latinCapitialLetterA: Character = "\u{41}"
let cyrillicCapitalLetterA: Character = "\u{410}"
if latinCapitialLetterA != cyrillicCapitalLetterA {
print("These two characters are not equivalent.") // Prints "These two characters are not equivalent."
}
---
output: These two characters are not equivalent.Note
In Swift, strings and characters are not locale-sensitive.
Prefix/Suffix Equality
You can check whether a string has a specific prefix or suffix by calling the hasPrefix(_:) and hasSuffix(_:) methods. Both methods take a String parameter and return a Boolean value.
The following example uses a string array to represent the scene locations in the first two acts of Shakespeare’s “Romeo and Juliet”.
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
"Act 1 Scene 4: A street outside Capulet's mansion",
"Act 1 Scene 5: The Great Hall in Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
"Act 2 Scene 4: A street in Verona",
"Act 2 Scene 5: Capulet's mansion",
"Act 2 Scene 6: Friar Lawrence's cell"
]You can call the hasPrefix(_:) method to count the number of scenes in Act 1:
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("There are \(act1SceneCount) scenes in Act 1.")
---
output: There are 5 scenes in Act 1.Similarly, you can use the hasSuffix(_:) method to count the number of scenes that take place in different locations.
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) mansion scenes; \(cellCount) cell scenes")
---
output: 6 mansion scenes; 2 cell scenesNote
The
hasPrefix(_:)andhasSuffix(_:)methods compare each string character by character to see if their extended grapheme clusters are standard equal.
Unicode Representations of Strings
When a Unicode string is written to a text file or other storage, the Unicode scalars in the string are encoded using one of several encoding forms defined by Unicode. Each small chunk of encoding in a string is called a code unit. These include the UTF-8 encoding form (encoding strings as 8-bit code units), the UTF-16 encoding form (encoding strings as 16-bit code units), and the UTF-32 encoding form (encoding strings as 32-bit code units).
Swift provides several ways to access the Unicode representations of a string. You can use a for-in loop to iterate over a string and access each Character value as an extended grapheme cluster.
Additionally, you can access the string’s value in three other Unicode-compatible ways:
- The collection of
UTF-8code units (accessed via the string’sutf8property) - The collection of
UTF-16code units (accessed via the string’sutf16property) - The collection of 21-bit Unicode scalar values, i.e., the string’s
UTF-32encoding form (accessed via the string’sunicodeScalarsproperty)
The following string consists of D, o, g, !! (DOUBLE EXCLAMATION MARK, Unicode scalar U+203C), and 🐶 (DOG FACE, Unicode scalar U+1F436), each representing a different kind of character.
let dogString = "Dog‼🐶"UTF-8 Representation
You can access the UTF-8 representation of a string by iterating over its utf8 property. This property is of type String.UTF8View, a collection of unsigned 8-bit (UInt8) values, each representing a character’s UTF-8 encoding:
| Character | D U+0044 | o U+006F | g U+0067 | ‼ U+203C | 🐶 U+1F436 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| UTF-8 Code Unit | 68 | 111 | 103 | 226 | 128 | 188 | 240 | 159 | 144 | 182 |
| Position | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
for codeUnit in dogString.utf8 {
print("\(codeUnit) ", terminator: "")
}
print("")
---
output: 68 111 103 226 128 188 240 159 144 182 In the example above, the first three decimal codeUnit values (68, 111, 103) represent the characters D, o, and g, whose UTF-8 representations are the same as their ASCII representations. The next three decimal codeUnit values (226, 128, 188) are the 3-byte UTF-8 encoding of the DOUBLE EXCLAMATION MARK. The last four codeUnit values (240, 159, 144, 182) are the 4-byte UTF-8 encoding of the DOG FACE.
UTF-16 Representation
You can access the UTF-16 representation of a string by iterating over its utf16 property. This property is of type String.UTF16View, a collection of unsigned 16-bit (UInt16) values, each representing a character’s UTF-16 encoding:
| Character | D U+0044 | o U+006F | g U+0067 | ‼ U+203C | 🐶 U+1F436 | |
|---|---|---|---|---|---|---|
| UTF-16 Code Unit | 68 | 111 | 103 | 8252 | 55357 | 56374 |
| Position | 0 | 1 | 2 | 3 | 4 | 5 |
for codeUnit in dogString.utf16 {
print("\(codeUnit) ", terminator: "")
}
print("")
---
output: 68 111 103 8252 55357 56374Again, the first three codeUnit values (68, 111, 103) represent the characters D, o, and g, whose UTF-16 code units are the same as their UTF-8 representations (since these Unicode scalars represent ASCII characters).
The fourth codeUnit value (8252) is a decimal value equal to hexadecimal 203C. This represents the Unicode scalar value U+203C for the DOUBLE EXCLAMATION MARK character. This character can be represented by a single code unit in UTF-16.
The fifth and sixth codeUnit values (55357 and 56374) are the UTF-16 representation of the DOG FACE character. The first value is U+D83D (decimal 55357), and the second is U+DC36 (decimal 56374).
Unicode Scalar Representation
You can access the Unicode scalar representation of a string by iterating over its unicodeScalars property. This property is of type UnicodeScalarView, a collection of UnicodeScalar values.
Each unicodeScalar has a value property that returns the corresponding 21-bit value as a UInt32:
| Character | D U+0044 | o U+006F | g U+0067 | ‼ U+203C | 🐶 U+1F436 |
|---|---|---|---|---|---|
| Unicode Scalar Code Unit | 68 | 111 | 103 | 8252 | 128054 |
| Position | 0 | 1 | 2 | 3 | 4 |
for scalar in dogString.unicodeScalars {
print("\(scalar.value) ", terminator: "")
}
print("")
---
output: 68 111 103 8252 128054 The first three UnicodeScalar values (68, 111, 103) still represent the characters D, o, and g.
The fourth codeUnit value (8252) is a decimal value equal to hexadecimal 203C. This represents the Unicode scalar U+203C for the DOUBLE EXCLAMATION MARK character.
The fifth UnicodeScalar value’s value property, 128054, is the decimal representation of hexadecimal 1F436. This is the Unicode scalar U+1F436 for the DOG FACE.
As an alternative to querying their value property, each UnicodeScalar value can also be used to construct a new String value, such as in string interpolation:
for scalar in dogString.unicodeScalars {
print("\(scalar) ")
}
---
output: D
o
g
‼
🐶