Pretrained Transformer for Low-Light Image Enhancement

Graphical Abstract
Abstract
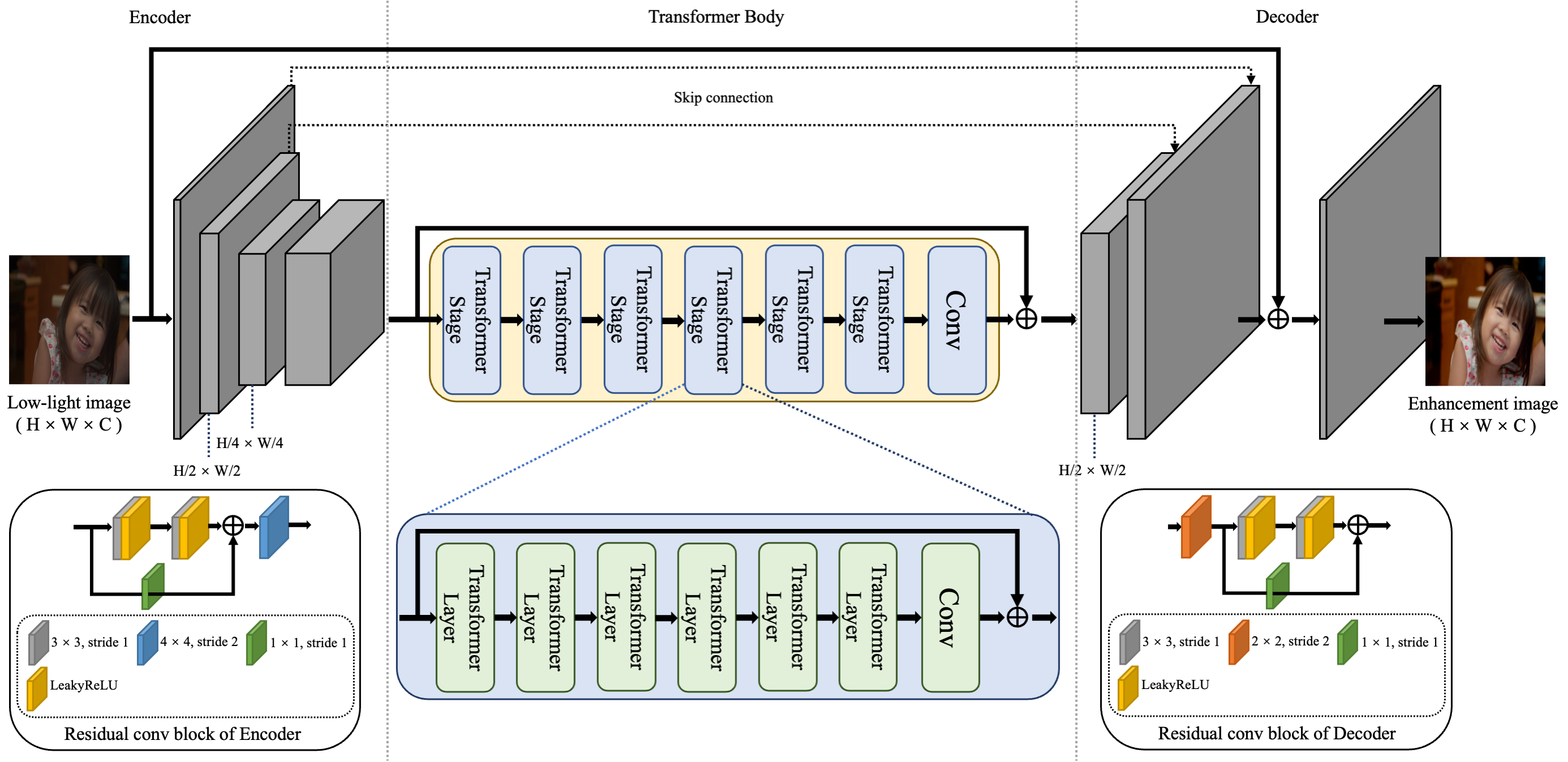
Low-light image enhancement is a longstanding low-level vision problem, as low-light images often suffer from severe aesthetic quality degradation. Current deep neural network-based low-light image enhancement methods have made significant progress on this task. Unlike mainstream CNN-based approaches, we propose an effective low-light enhancement solution inspired by Transformers, which have demonstrated superior performance across various tasks, to address this issue. The key components of this solution include an image synthesis pipeline and a robust Transformer-based pretrained model named LIET. Specifically, the image synthesis pipeline consists of illumination simulation and real noise simulation, enabling the generation of more realistic low-light images to alleviate the data scarcity bottleneck. LIET incorporates a pair of simplified CNN-based encoders/decoders and a Transformer backbone, capable of efficiently extracting global/local contextual features at relatively low computational cost. We comprehensively evaluate the proposed method through extensive experiments, and the results demonstrate that our solution is highly competitive with state-of-the-art methods. All code will be released soon.
.")

